图像中文描述问题融合了计算机视觉与自然语言处理两个方向,对图片输出一句话的描述。
描述句子要求符合自然语言习惯,点明图像中的重要信息,涵盖主要人物、场景、动作等内容。
数据集

数据来自2017 AI Challenger
数据集对给定的每一张图片有五句话的中文描述。数据集包含30万张图片,150万句中文描述。
训练集:210,000 张
验证集:30,000 张
测试集 A:30,000 张
测试集 B:30,000 张
数据集下载,放在data目录
模型结构
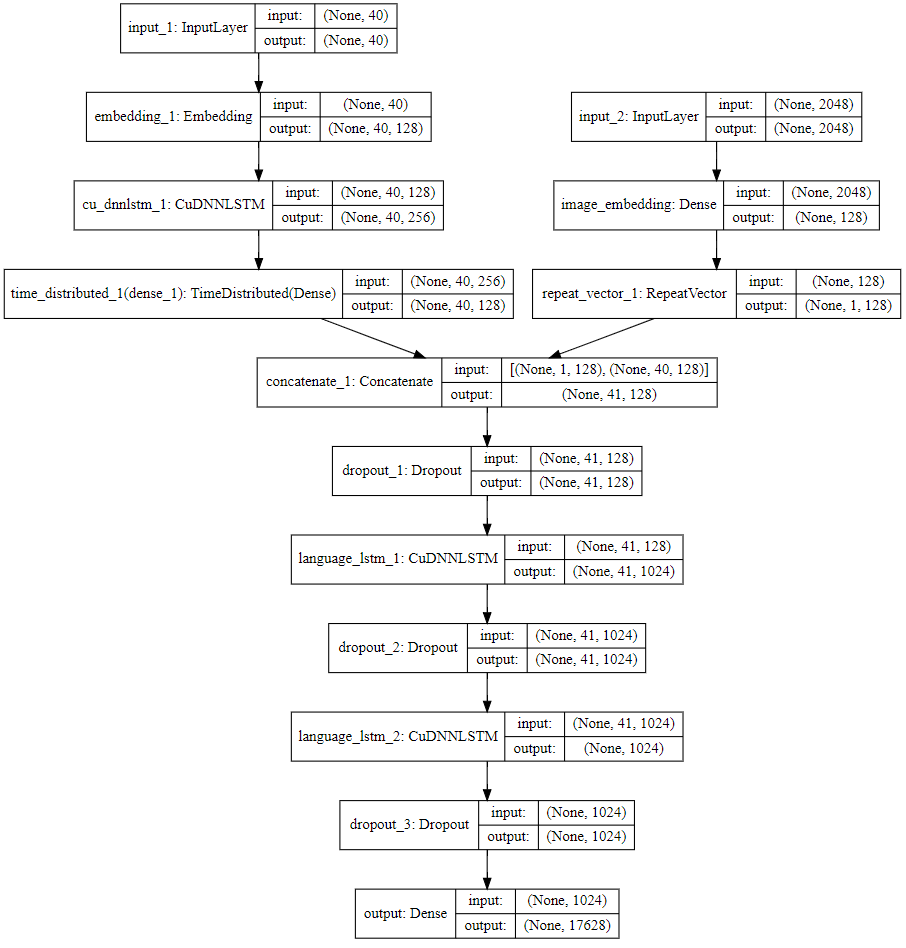
模型的输入数据由两个元素的列表构成,一个是文本特征,一个是图像特征。
输入的文本数据是40维向量,经过Embedding词嵌入层,文本被映射到128维向量空间,Embedding层的作用是将稀疏的One-hot向量编码成维数较低的矩阵,经过LSTM层与TimeDistributed包装过的Dense层,结果为(40,128)的向量。
输入的图像数据是ResNet50提取出的2048维特征向量,经过Embedding层和RepeatVector扩充维度都,得到(1,128)的向量。

将两种特征通过Concatenate函数融合成(41,128)维特征,经过第一个Dropout层防止过拟合,第一层LSTM网络,第二个Dropout层,第二个LSTM网络,第三个Dropout层,最后通过1024*17628的全连接层输出17628维数据,维数对应预处理数据集得到的词库大小。
训练过程
模型通过backward.py文件计算反向传播并训练
使用Adam优化器,学习率为0.000051
adam = keras.optimizers.Adam(lr=5e-5)
损失函数为categorical_crossentropy多分类对数损失1
new_model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accuracy'])
训练过程中使用TensorBoard可视化训练曲线1
2
3
4
5
6 tensor_board = keras.callbacks.TensorBoard(log_dir='./logs', histogram_freq=0, write_graph=True, write_images=True)
```
使用以下方法优化模型训练过程:
使用ModelCheckpoint保存一个轮次中效果表现最好的模型训练模型
```bash
model_checkpoint = ModelCheckpoint(model_names, monitor='val_loss', verbose=1, save_best_only=True)
使用EarlyStopping函数防止过拟合1
early_stop = EarlyStopping('val_loss', patience=patience)
使用ReduceLROnPlateau函数调整学习率,当评价指标不在提升时,减少的学习率为lr = lr*factor1
reduce_lr = ReduceLROnPlateau('val_loss', factor=0.1, patience=int(patience / 5), verbose=1)
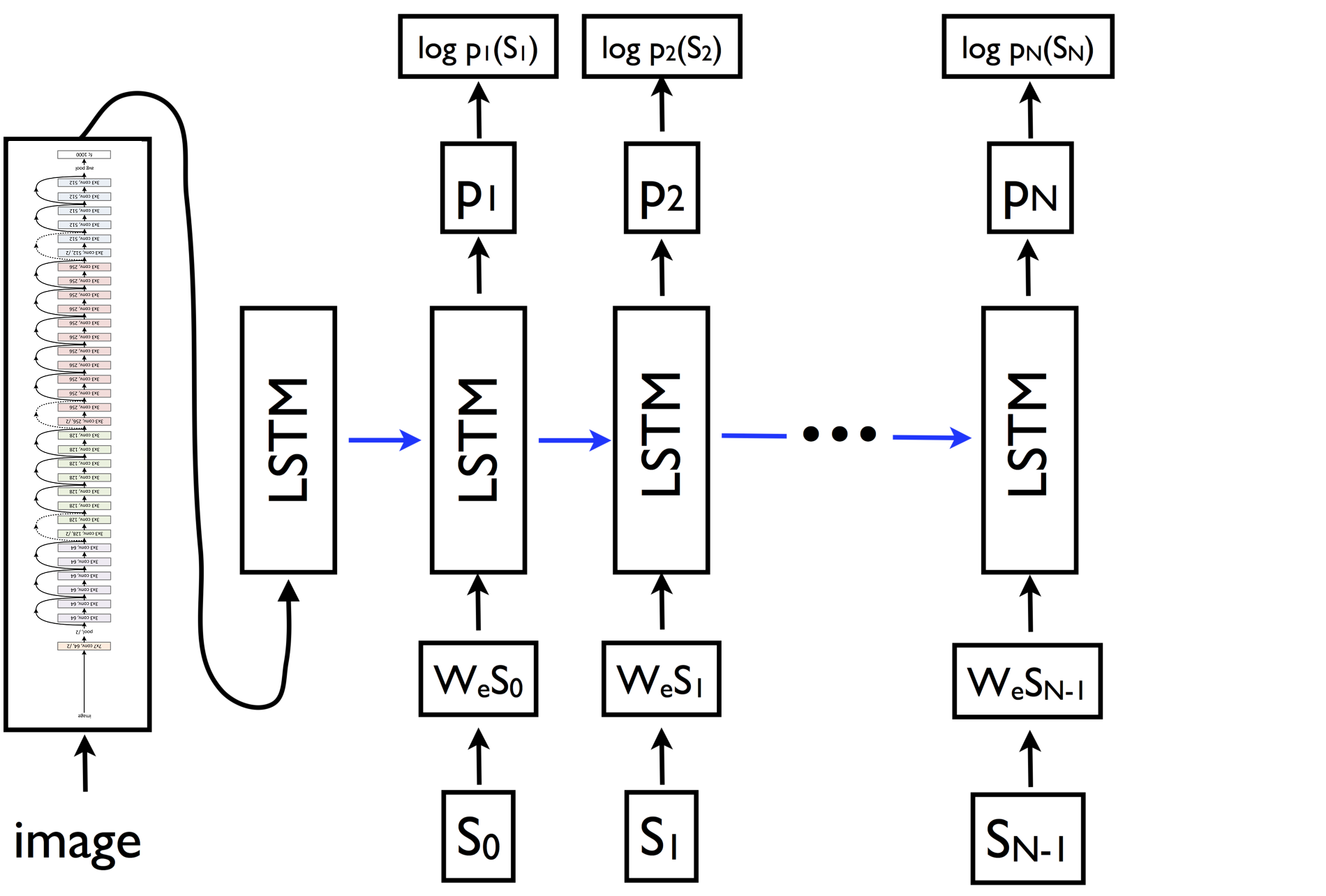
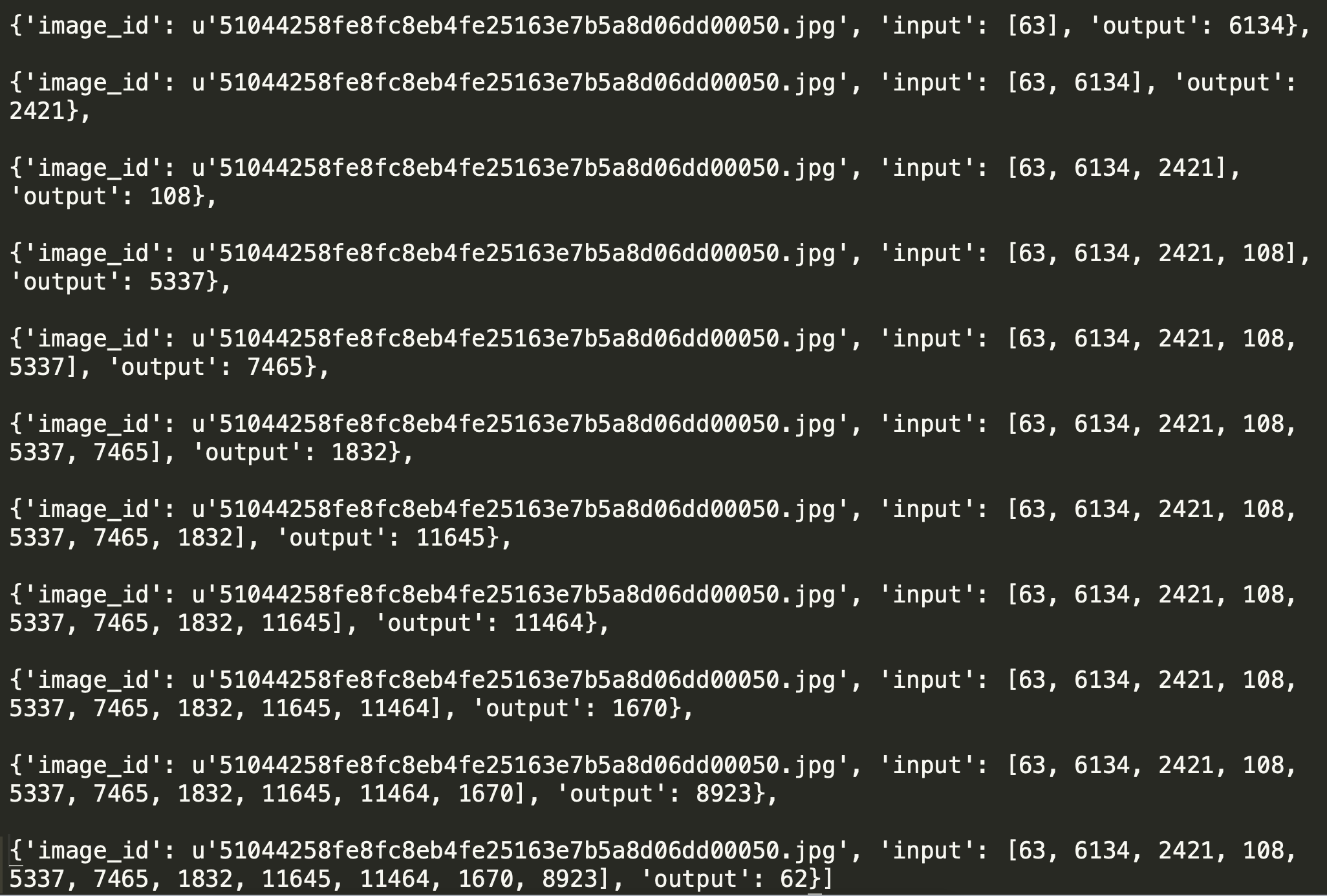
模型训练时喂入的数据通过data_generator文件按批次生成,输入的x是图像的2048位特征和经过向量化处理的句子,期望得到的标签y是这句话的下一个字,如下图
Seq2Seq模型
所有输出端,都以一个通用的
Beam Search
Beam Search(集束搜索)是一种启发式图搜索算法,通常用在图的解空间比较大的情况下,为了减少搜索所占用的空间和时间,在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。这样减少了空间消耗,并提高了时间效率,但缺点就是有可能存在潜在的最佳方案被丢弃。
评价指标
BLEU是一种通过计算候选译文和参考译文中n 元词共同出现的程度,来衡量候选句子与参考句子相似度的机器翻译度量方法。
ROUGE是用来评价文本摘要算法的自动评价标准集,本次图像中文描述比赛主要采用其中的ROUGE_L作为评价标准。ROUGEL 是基于LCS(Longest Common Subsequence)的一种测量方法。LCS是序列X 和序列Y 的最大长度公共子序列的统称。
METEOR 是用来评价机器翻译输出的标准。该方法将候选语句和参考语句的词进行逐一匹配,METEOR需要预先给定一组类似于WordNet的同义词库,通过最小化对应语句中连续有序的块来得出。METEOR的计算为对应候选语句和参考语句之间的准确率和召回率的调和平均。
CIDEr 通过对每个n元组进行Term Frequency Inverse Document Frequency (TF-IDF) 权重计算,来衡量图像描述的一致性。
Attention注意力机制
Reference Paper: Show, Attend and Tell: Neural Image Caption Generation with Visual Attention https://arxiv.org/pdf/1502.03044v3